
티스토리 뷰
추석에 학교에 아무도 없어서 말할 사람이 없다 보니 (?) 글을 쓰게 되었다.
연구 방법론 석사 수업을 밑바탕으로 여러 자료를 읽으며 정리해보려고 한다.
공부하면서 정리하는 것으로, 글에 오류가 있을 수 있다는 것을 미리 밝힌다.
Course objectives
Empirical study를 면밀하게 디자인하고 데이터를 분석하고, 인사이트를 이끌어내는 방식을 가르친다. 양적 연구를 위한 통계학적 기법들을 익히면서 과학적 증거를 이용한 연구를 목표로 한다.
정량 분석
현상을 일반화하기 위해 객관적인 측정 척도로 데이터를 정량화한다.
연구자는 모두가 동의할 수 있는 일반적인 사실을 강조한다.
정성 분석
직관적인 통찰로 현상의 의미를 이해한다.
연구자는 각각의 현상학적인 관점을 반영한다.
4가지 관점으로 차이를 설명해보자면 아래와 같다. (1)
두 가지 연구 방법은 배타적인 것이 아닌, 상호보완적인 관계다.
|
assumption |
purpose |
approach |
researcher's role |
|
|
정량적(quantitative) |
객관적인 현실은 사실에 기반함 |
원인 탐색 |
실험적이거나 상호관계적 연구 |
실험 셋팅과 분리되어 있음 |
|
정성적(qualitative) |
객관적인 현실은 사회적으로 구성됨 |
이해 |
민족지학적 연구 |
실험 셋팅에 들어와 있음 |
Variable
연구에서 변수를 설정하는 것이 가장 중요하다. 어떻게 묻느냐에 따라서 변수의 유형이 달라진다.
- Ratio scale
절대 0이 존재
사칙 연산이 가능
순서 사이의 간격이 균등
e.g. 섭씨, kg ... - Interval scale
순서 사이의 간격이 균등
e.g. likert-scale ... - Hierarchical scale
순서 관계 척도
e.g. 등수 ... - Nominal scale
속성 분류 척도
e.g. 성별, 색상 ...
dependent / independent
Null hypothesis / Alternative hypothesis
1종 오류
기본 용어
가장 기초적인 개념들을 소개한다.
population: 현실적으로 모집단 자료를 가지는 경우는 거의 없다.
보통은 내 연구의 표본에서 도출된 결과가 실험값이라는 것을 구분하기 위한 목적으로 사용한다.
sample: population을 대치할 수 있는 sampling 은 중요하다.
| population parameter | sample statistic | |
| population size | N | n |
| mean | µ | x̅ |
| standard deviation | σ | s |
세상에는 여러 요인들로 인해서 불확실성이 발생한다.
-
내재된 확률성 : 랜덤 하게 작동하는 시스템들이 존재한다. (e.g. 주사위)
-
불완전한 관측 가능성 : deterministic system이라도, 모든 변수를 확인할 수 없는 경우를 말한다.
-
불완전한 모형화 : 관찰한 정보의 일부를 버려야 하는 경우를 말한다. (e.g. 데이터 정규화 작업)
probability : 불확실한 것들을 표현하는 방식이다. 참인지 거짓인지를 결정하는 논리를 불확실성까지 다룰 수 있도록 확장한 것이다. 두 가지 관점으로 확인해볼 수 있다.
- frequentist probability: 특정 사건이 일어날 비율이다.
'alternative hypothesis에 비해서 null hypothesis가 참이 아니라는 significant evidence 가 존재하는가'에 대한 판단을 하는 전통적인 가설검정에서 사용한다 - Baysian probability: 믿음의 정도.
'대립 가설과 귀무가설 또는 아무것도 아닌 것 중에서 어떤 것에 속하는가'에 대한 판단을 하는 가설검정에서 사용한다.
random variable: 여러 값을 무작위 하게 가지는 변수이다. 이산(discrete)일 수도, 연속(continuous)일 수도 있다.
probability distribution: random variable이 가질 수 있는 값에 대한 확률이다. random variable이 이산인지, 연속인지에 따라서 이러한 분포를 서술하는 형태가 달라진다.
- probability mass function

x = y일 확률이 곧 P(y)인 것이다.
확률을 모두 더한 값은 1이어야 하고, 이 작업이 normalization이다. - probability density function
 random variable이 연속적일 때는, 딱 하나의 값을 가질 확률을 구할 수가 없다. 온도가 21.0도인 확률은 0에 가깝다. 21.00129312... 는 결코 21.0000000 이 아니다.
random variable이 연속적일 때는, 딱 하나의 값을 가질 확률을 구할 수가 없다. 온도가 21.0도인 확률은 0에 가깝다. 21.00129312... 는 결코 21.0000000 이 아니다.
그래서 x = y 일 확률이 아닌, 특정 구간에 속할 확률을 구해야 한다.
확률 분포 P(x)에 대한 함수 f(x)의 expectation: P에서 뽑은 x들에 대한 f값들의 평균.
f(x)가 확률 분포 P(x)를 따를 때, 무슨 값이 나오면 좋겠나 생각해보면 된다.
variance: random variable x의 함수가 확률 분포에서의 x 값들에 따라 얼마나 변하는지를 나타내는 측도.
값이 평균에서로부터 얼마나 퍼져있는지를 측정할 수 있는 것이다. 단위 역시 제곱이 된다.

standard deviation: 분산의 제곱근. 단위를 x 값과 동일하게 나타낼 수 있다.
population과 sample의 standard deviation 산출 식에는 차이가 있다. sampling으로 얻은 데이터의 불완전성을 감안하여, N-1을 분모로 사용한다.
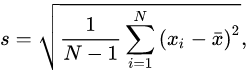
covariance: 2개의 random variable의 상관정도. 두 값의 선형 관계 그리고 값의 규모가 어느 정도인지 알려준다.
양수인 경우: 두 변수가 동시에 큰 값(혹은 상승하는 경향)을 가지는 경향.
음수인 경우: 한 변수가 상대적으로 클 때 다른 한 변수는 상대적으로 작은 값.
correlation: 변수의 규모와는 상관없이 변수들의 관계만 측정하기 위해 각 변수의 기여를 정규화한 것이다.
두 변수가 독립이면 correlation은 0이고, 종속이면 correlation은 0이 아니다. 종속이라도 correlation은 0일 수 있는 것이다.
p-value
significance
one-tailed
two-tailed
degree of freedom
Distribution
Normal distribution
z-score
Chi-square distribution
T-distribution
F-distribution
참고 자료
(1) William Firestone, Educational Researcher
(2) en.wikipedia.org/wiki/Probability_distribution
(3) Ian Goodfellow, Deep Learning
'Research > Research methodology' 카테고리의 다른 글
| [디자인 연구 방법론 - t-test와 One-way ANOVA] 평균 비교 (0) | 2020.10.02 |
|---|---|
| [디자인 연구 방법론 - chi-square test] 1. frequency 비교 (0) | 2020.10.02 |
- san diego
- santa barbara
- San Francisco
- 카카오뱅크
- 미국
- Sustainability
- 신한은행
- 학회
- SIGGRAPH
- 그리니치
- 전월세대출
- lalaland
- 인생의 발견
- SanDiego
- 성격의 탄생
- 게티
- 부
- 연구방법론
- 여행
- 성격심리학
- 일상
- 라라랜드
- 성차별
- MOCA
- 청년전세대출
- 성격특성
- 인생의발견
- LA
- 페미니즘
- Irvine
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |